BLOG DO ATLÂNTICO
Federated Learning seeks to boost the use of artificial intelligence in the corporate world

If you are tech-savvy and like to keep up on the latest news in artificial intelligence, you’ve probably heard the term “federated learning”. But if you’ve never heard of it, or want to learn a little more, this could be a good read for you.
Federated learning is nothing more than an alternative model designed to improve the algorithms that dominate many aspects of human life. Have you ever researched a topic, only to find suggestions or advertisements about the very subject you were researching on your social networks? Well, in a traditional system, collected personal data is sent to a central server where it is analyzed and the relevant information is used to change the algorithm. Federated learning enables artificial intelligence algorithms to acquire experience from a variety of sources of data located in different places.
According to data scientist Cleilton Lima Rocha, with this approach, several organizations can already collaborate in the development of learning models without having to share confidential data directly with each other. “Federated learning offers a solution that enhances user privacy because the personal data remains on the user’s device. Algorithms are enhanced directly on the devices and only return model settings that can improve an overall, shared model, rather than the data as a whole. This allows companies to improve their algorithms without having to collect all of a user’s data. This provides a solution focused on privacy,” explains Cleiton.
According to Cleilton, in recent years there have been significant advancements in the use of artificial intelligence, with machine learning and data science in corporate applications. Cleilton gives as some examples; financial institutions that have adopted machine learning models to prevent transaction fraud and calculate payment risk; and companies in e-commerce that have developed recommendation systems to leverage cross-selling and up-selling, and thus increasing profits. “These are examples of applications that benefit from the volume of data that institutions have on their customers”, explains Cleilton.
Development of smart solutions
The ecosystem of frameworks, libraries, programming models and platforms in Big Data has raised the potential for developing intelligent solutions and, among them, is the principle of locality. This means we can carry out the execution and processing of the code where the data is. “So, as code processing has moved to where the data is in a cluster, (a term used to refer to the system architecture that joins two or more computers together as if they were just one) the same is happening for the intelligent models where, they too are moving to where the data is. That is to say, they are trained and run directly on the devices, especially when data privacy is essential and emphasized as part of the solution”, explains the data scientist.
Data Privacy
Privacy policies and data ethics have been discussed by governments worldwide. Laws were created to guarantee the rights of data owners and to limit and define obligations of institutions that exploit the existing value of the data. The “General Data Privacy Regulation” that has been enforced in the European Union (EU) and the “General Data Protection Law” that is being implemented in Brazil, are some of the currently existing laws.
When we think about the ethics around privacy, sharing and decision-making of data, we are faced with some questions: “Who owns the data?”; “How do we value different aspects of privacy?”; “How can we obtain informed consent?”; among others. These issues should be reflected upon, especially when it comes to smart solutions where the approach is centralized.
Centralized Learning vs. Federated Learning
The traditional method of centralized machine learning, poses a high risk to data protection due to the need to keep data within reach of the learning model. In addition, there is a cost associated with maintaining data in the cloud or in the core infrastructure that will necessarily require a greater managerial demand for the security of data assets. It will also consume more computing resources and energy resources. According to Cleilton, in this method intelligent models have access to all available data and can be developed, trained, evaluated and evolved in a totally centralized way.
As a disadvantage, the centralized approach has a high data latency, as the data needed for training the models, for predictions, ratings and/or recommendations is usually sent and processed by the models that exist within the cloud. “If the model were on the device, it would have immediate access to the user’s data, sending only the most necessary information to the cloud. You would therefore have a personalized, intelligent model with a high performance to boot. It would even improve the user experience when interacting with the application”, he explains.
These were some of the things that motivated the emergence of Federated Learning, where the approach is to build a machine learning algorithm that keeps data on the device. Therefore, it is possible for each device to have its own private and local data and also to provide a generalized learning solution as well as personalized learning with flexible data managed in real time.
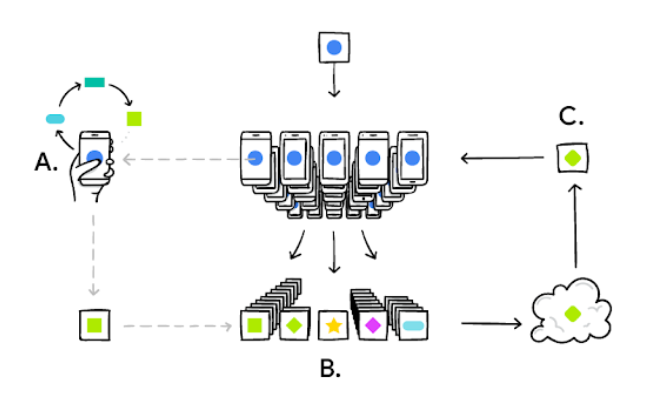
The overall device is customized locally, based on user interaction and data (A). Multiple user updates are aggregated (B) to form a general consensus about the changes brought about (C) in the overall model that will be shared again. This process is repeated cyclically.

Types of Federated Learning
The two main types of Federated Learning are horizontal and vertical. But there is also Federated Transfer Learning. The main differences are:
Horizontal Federated Learning: the set of variables, or data attributes, are the same for all users, ie, the process works by introducing similar data sets into devices in comparable spaces.
Example: A financial institution wants to anticipate the risk of a transaction being fraudulent before executing it based on user interaction with the application. In this context, a customer of institution X has exactly the same set of attributes (e.g. account type and limit, amount, day, time, transaction type, etc.) as another customer, however other values are different and each customer would have their personal template which would run on their devices.
Vertical Federated Learning: this is where there is more than one data source with a set of distinct variables for each source. However, only the samples existing in the data sources are used in the training of the model. This type of learning would be applicable to the scenario where we have two financial institutions, A, a digital bank and B, a credit card issuer. They could share knowledge and create a collaborative fraud prevention and prediction solution, albeit with a structure of distinct attributes and without sharing their customers’ data. Another example would be to have an intelligent model for calculating the risk of death for patients, taking data from different sources belonging to SUS (the National Brazilian Unified Health System), and data from the same patients in a network of health plans. The two institutions would share the knowledge existing within the data, but not the patients’ sensitive data and information.
Federated Learning can be used in several segments, such as: health, finance, agriculture and e-commerce, among others. Such applications are encouraged in solutions where data privacy is extremely sensitive, also where the computation happens inside edge computing, such as IoT devices, smartphones, mobile devices or embedded smart systems. “With the increase of devices exploiting edge technology and driven by the movement to move computing from the cloud to edge, we will increasingly see solutions for artificial intelligence within edge computing (Edge AI), adopt federated learning in their developments,” says Cleilton.
Posts relacionados
Conteúdo rico no seu e-mail
Assine nosso conteúdo e receber os melhores conteúdos sobre tecnologia e inovação.